In PAI, a Learning Set organizes all of the necessary data and parameters for training, including the data samples, the data preparation parameters and the neural network settings.
Note that any necessary data preparation should be done before creating or extending a Leaning Set.
Learning Set Creation
To create a Learning Set or start a training run, select Edit Learning Set (Training) from the View + AI menu:
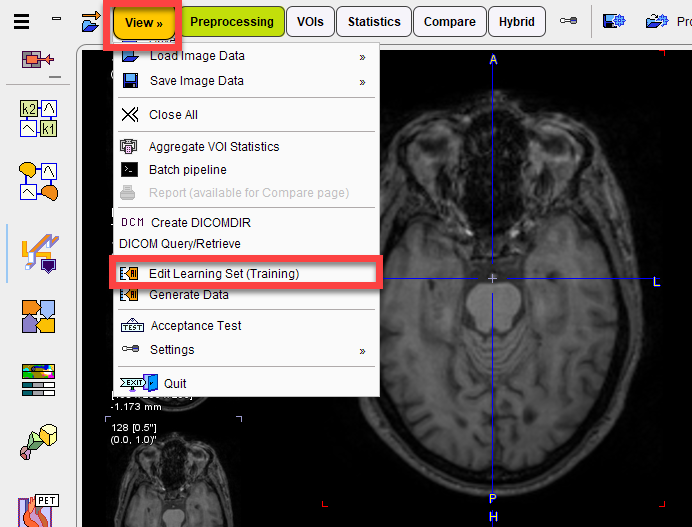
A dialog window appears that lists the existing learning sets in the upper section. It allows new learning sets to be created and existing leaning sets to be extended in the lower section.
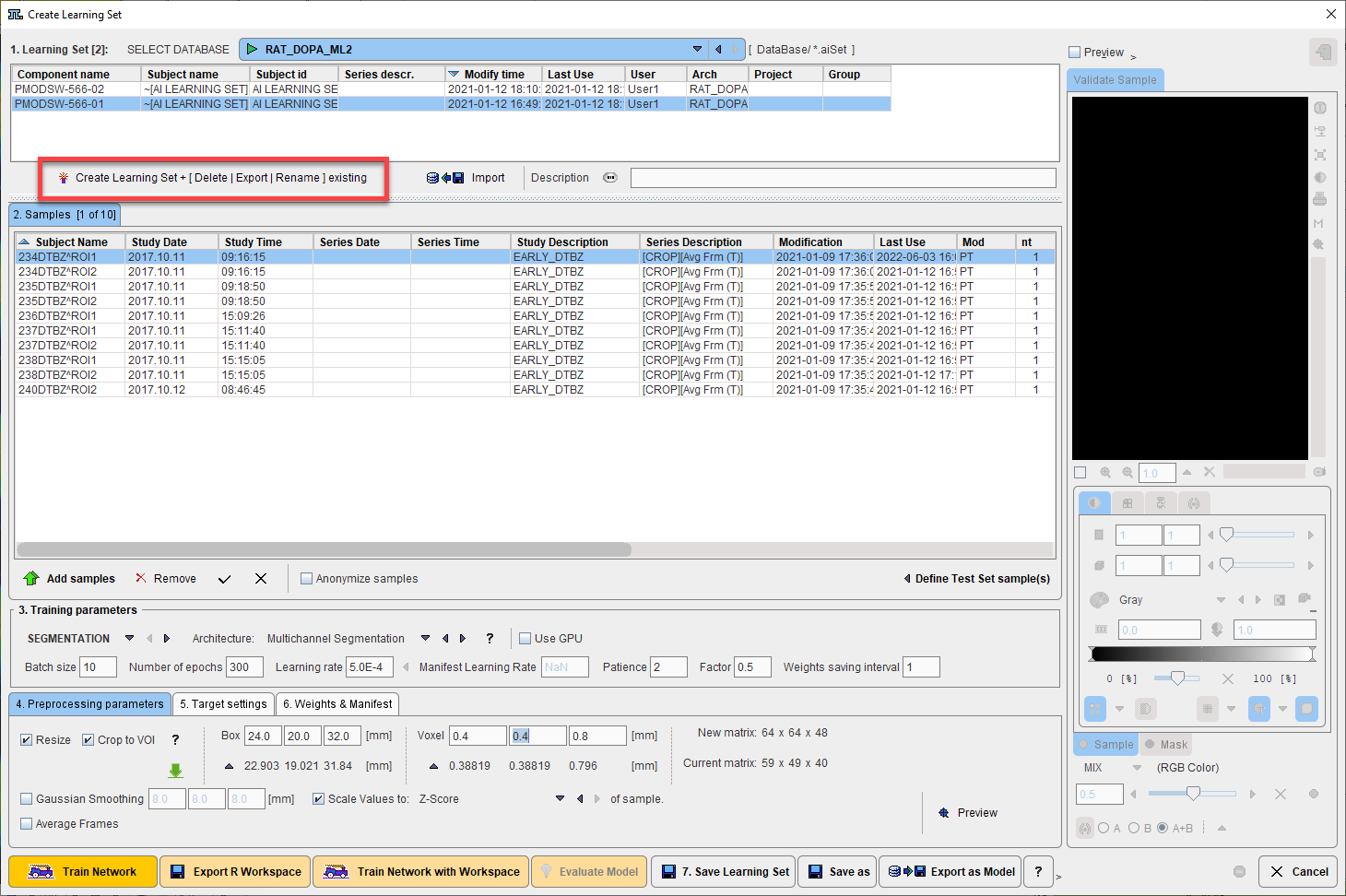
A text description can be appended to the Learning Set using the Description navigation button:
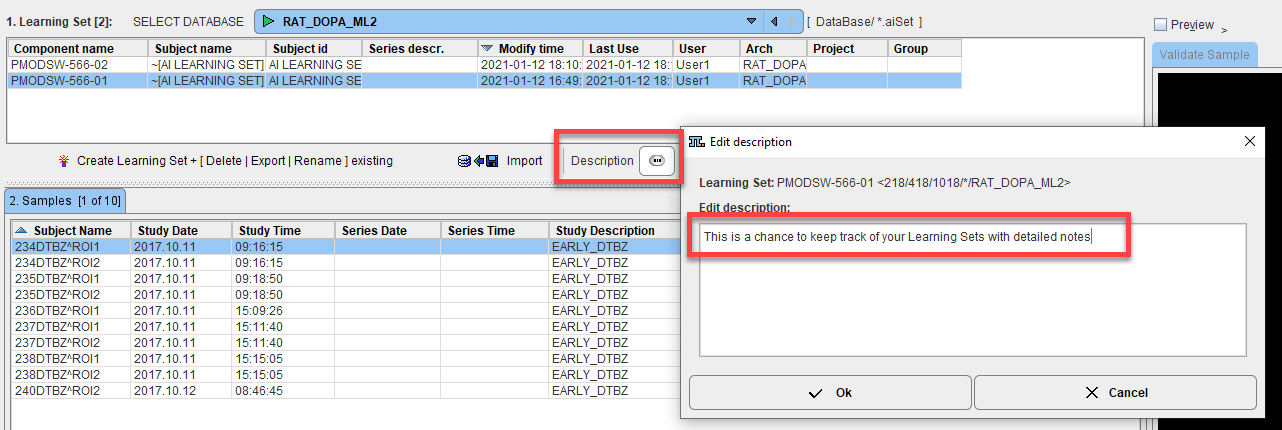
Existing Models can also be imported using the Import Learning Set button. A database containing the same samples as used for training, with same database and sample naming, is required. The corresponding weights and manifest files will also be imported and the Model available via the database for Prediction. This mechanism can be used to import models that were trained on different machines (or cloud computing).
Learning Set Content
The next step is to add training samples. First select the learning set in the 1. Learning Set list, then select Add Samples at the bottom of 2. Samples.
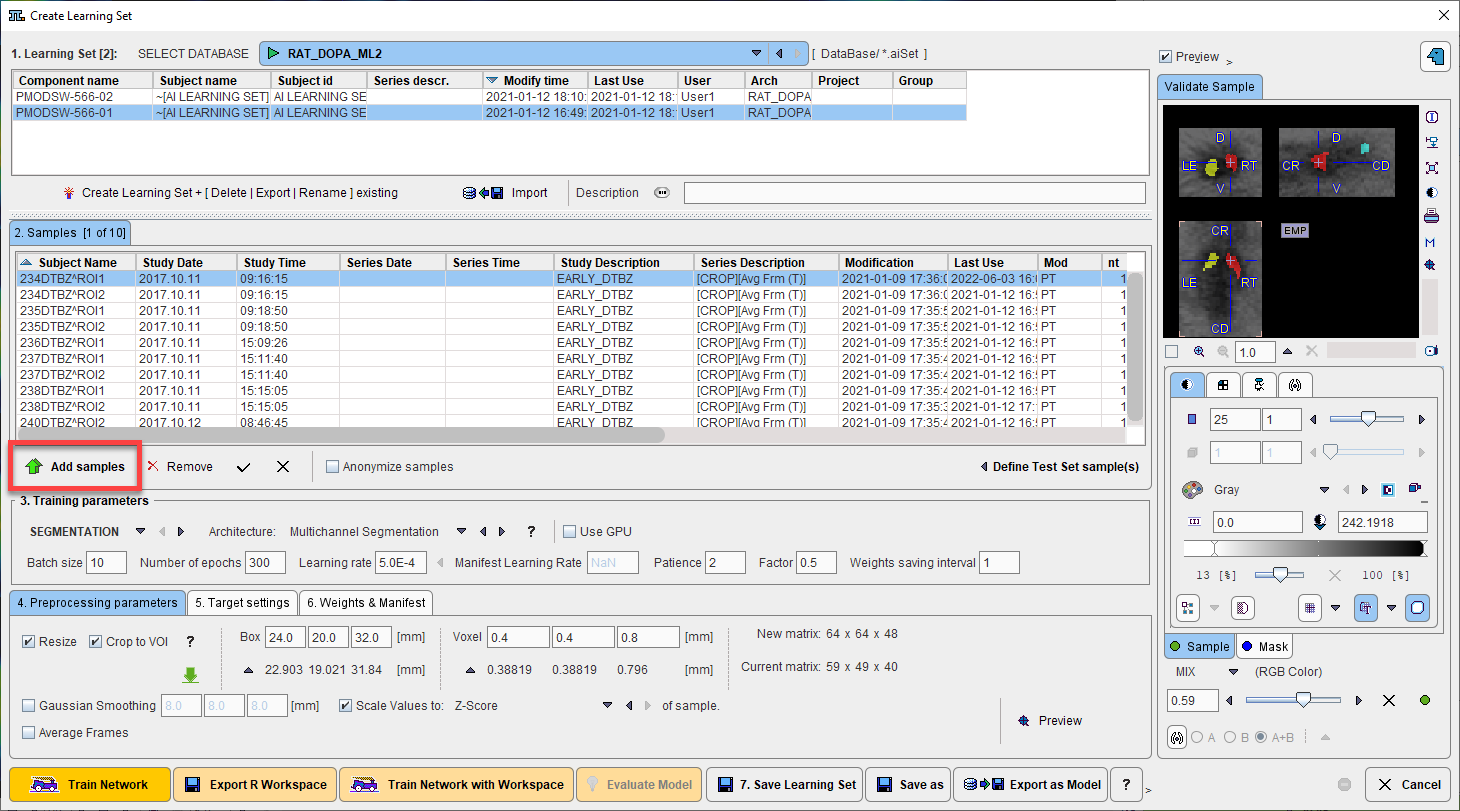
A dialog window appears for selection of the input images. The flat database view

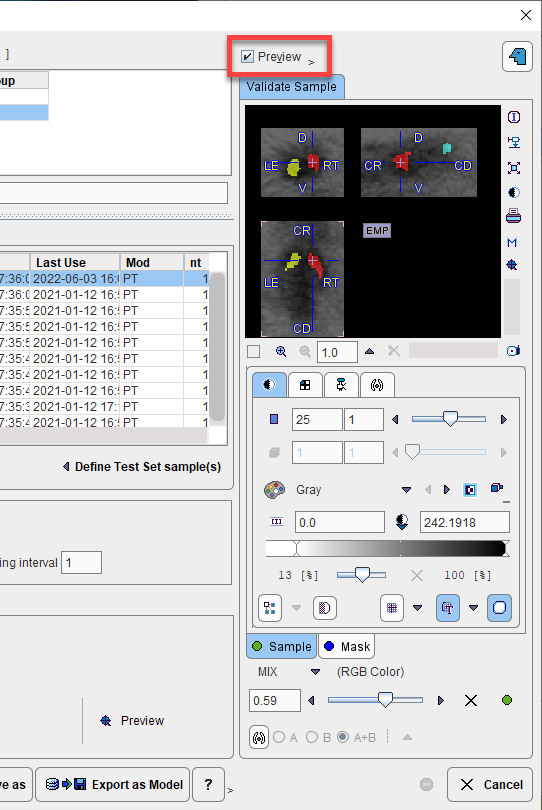
and advanced filtering options are useful to list the only the image series which are first in the Associated list. Select all appropriate series from the filtered list and Set Selected. The dialog window is closed and the samples added are listed in 2. Samples. For a quick quality control, the fusion of the sample image and the corresponding reference segment can be shown in the Validate Sample area by activating the Preview box:
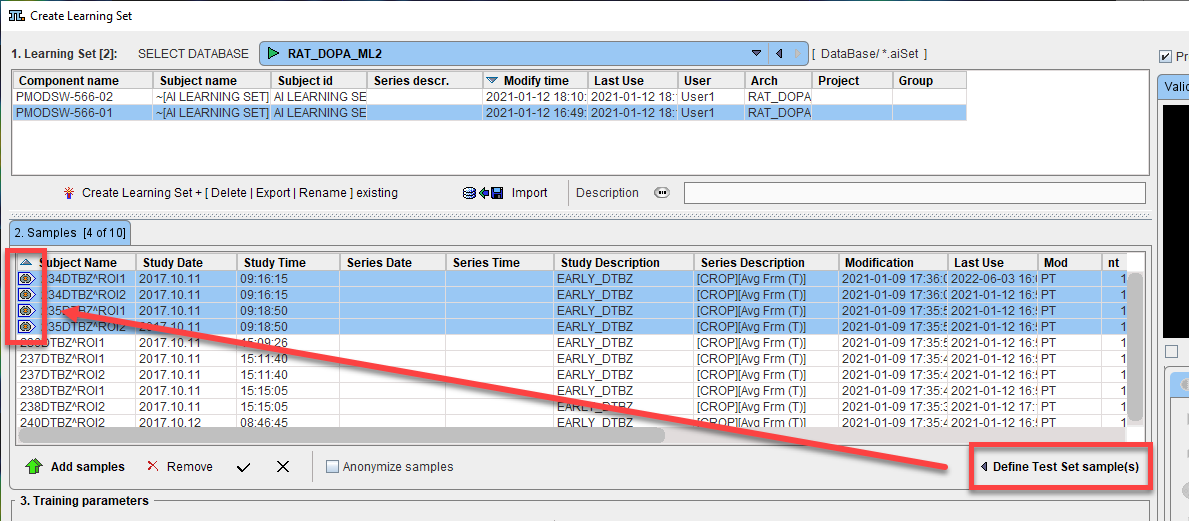
The Define Test Set Samples option is used as part of model evaluation after successful training. A number of samples may be excluded from training and “held back” for model evaluation. These samples can be selected in 2. Samples and marked as Test samples using the Define Test Set Samples button. Following training, an automated model evaluation process can be started using these samples using the Evaluate Model button. Prediction will be run in R Console and each predicted segment compared to the reference associated with the sample. An average loss value for the test set samples will be returned.
Samples may be Anonymized for training by checking the checkbox Anonymize samples. This is particularly relevant for training on cloud-computing infrastructure.
Architecture Selection & Settings
In 3. Training parameters, architecture to be used and the training settings are configured.
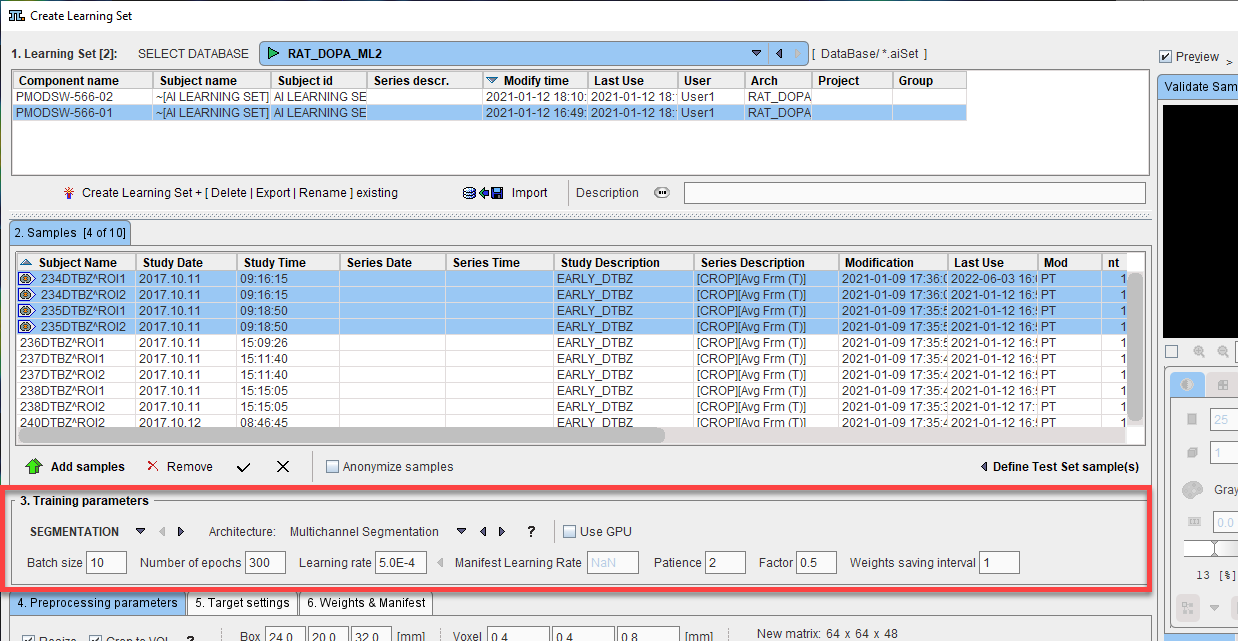
The AI task (Segmentation or Classification) is selected on the left, followed by the neural network Architecture.
The neural network architecture is selected from the drop-down menu Architecture. The list corresponds to the the content of the Pmod4.4/resources/pai folder, where the neural network configurations are stored in sub-directories. See Architectures included in Distribution
Note that the architectures provided by PMOD are designed to be retrainable. For example, the Multichannel Segmentation architecture was initially tested for the 4 input series, 3 segment output MICCAI BraTS example case, and was successfully reapplied for the Rat Brain Dopaminergic PET example case. This retraining is described as a Case Study later in this documentation.
The checkbox Use GPU allows you to choose between training using the CPU or available/compatible GPU. Note that the Classification architecture SVM can only use CPU.
The training parameters for SEGMENTATION are:
•Batch Size: This parameter defines the number of samples that are processed before the internal model parameters are updated.
•Number of Epochs: Defines the number of times that the learning algorithms processes the entire training data sets. The length of the vector of loss values recorded in the Manifest corresponds to the number of epochs. Hence multiple epochs are required to observe an evolution of the loss value through training. During training a plot of the loss value (y-axis) by epoch (x-axis) is displayed, allowing the user to gauge the progress of training (and stop training if a plateau in loss value is observed).
•Learning Rate: Defines the rate of change of the Weights. (For a Learning Set that has been used for training the final learning rate reported in the Manifest is shown)
•Manifest Learning Rate: if the model is being retrained and there is an existing manifest, the Learning Rate recorded in that manifest is displayed here (the field is not editable)
•Patience: Defines how frequently (after which number of epochs) the validation loss is compared (and hence learning rate altered)
•Factor: Defines the factor by which the Learning Rate will be adjusted when the validation loss is found to increased from one epoch to the next (or for interval of epochs defined by Patience)
•Weights saving interval: Defines how frequently the weights file will be saved (e.g. Weights saving interval = 1, save after every epoch)
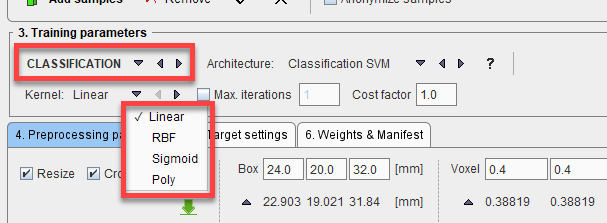
The training parameters for CLASSIFICATION vary by SVM kernel selected (see https://scikit-learn.org/stable/modules/generated/sklearn.svm.SVC.html for additional details):
•Linear: Max. iterations, Cost factor
•RBF: Max. iterations, Cost factor, Gamma (Auto, Scale, User defined)
•Sigmoid: Max. iterations, Cost factor, Gamma, Coefficient
•Poly: Max. iterations, Cost factor, Gamma, Coefficient, Degree
Additional architectures available for Classification are ResNet50 and Image Classification. Contact us for more information.
Data Preparation
In 4. Preprocessing parameters, the data preparation steps are configured.
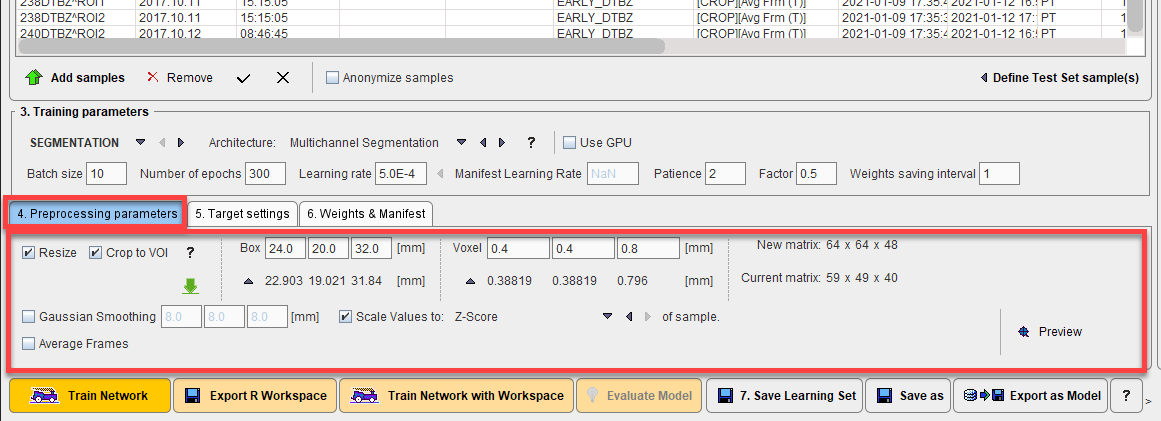
The available data preparation steps are:
•Resize: input samples may not all have the same image dimensions, pixel size or field-of-view. Standardization is beneficial to training the neural network. This can be achieved through a combination of cropping and interpolation. Crop to VOI: Enables cropping to the associated VOI as described in Data Preparation or to a fixed Box and Voxel size, defining the New matrix. The ![]() icon retrieves the current box and voxel size from the sample selected in 2. Samples to make a comparison between the New matrix and Current matrix easier.
icon retrieves the current box and voxel size from the sample selected in 2. Samples to make a comparison between the New matrix and Current matrix easier.
•Gaussian Smoothing: Input image smoothing to reduce noise.
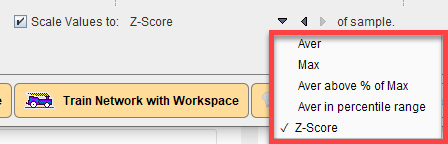
•Scale Values to: Normalization of the pixel value range by scaling according to a method selected:
•Average Frames: Reduce the dimensions of the input data by averaging the available frames.
•For Classification additional options for Image Reduction are available. The tool tips provide additional information about the methods available:
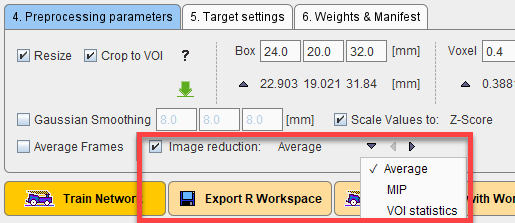
- Average: average of available slices in z direction, creating a 2D image from 3D input
- MIP: calculates the maximum intensity projection in z direction, creating a 2D image
- VOI Statistics: reduces the sample to a vector by calculating a chosen statistic in associated VOI(s). A subset of the VOIs available in an associated VOI file can be defined using the Select VOIs checkbox. The VOIs to be selected can either be defined by manually entering the VOI numbers to be used or by checking the desired VOIs in the interface provided by From VOIs.
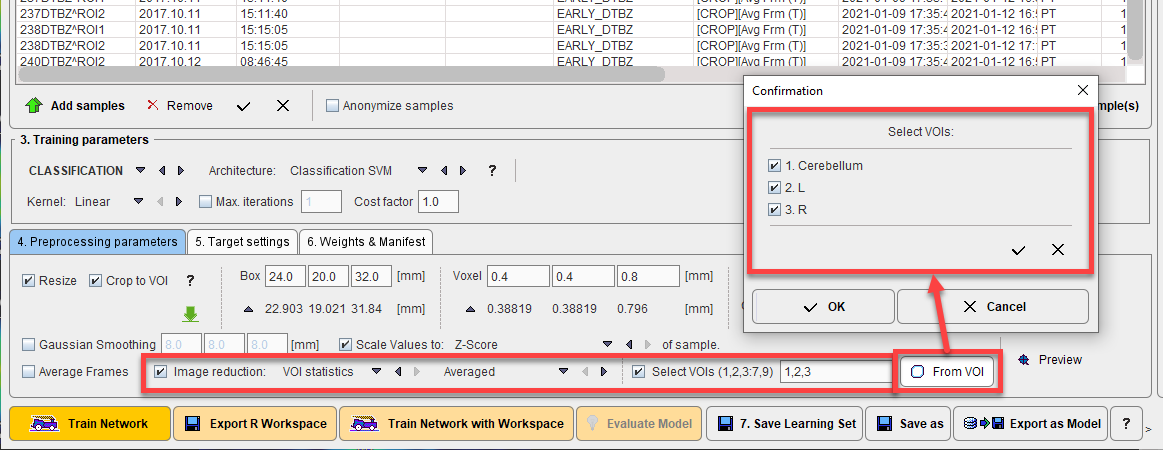
The effect of the selected Preprocessing parameters can be examined by generating a Preview of the sample after preprocessing using the Preview button:
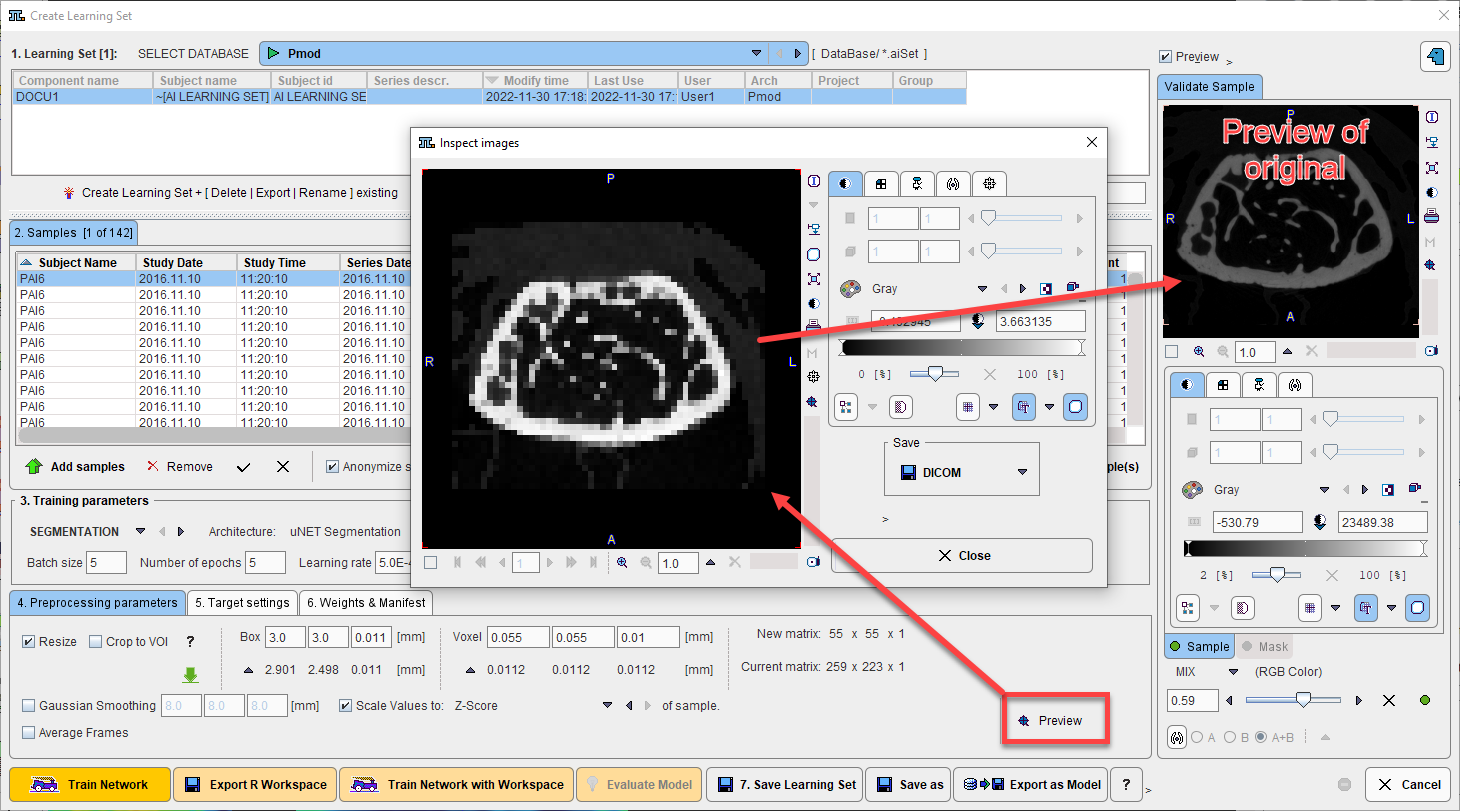
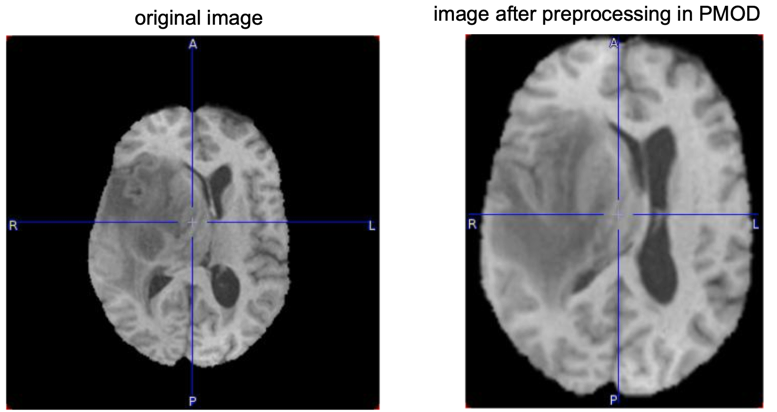
Note that as an alternative to such pre-processing steps, the input images could be (manually) pre-processed in other PMOD tools. In this case the user must ensure that identical operations are applied to the input images before prediction.
Data preparation helps to reduces the amount of unnecessary information in the sample and standardize images which were not acquired using the same protocol.
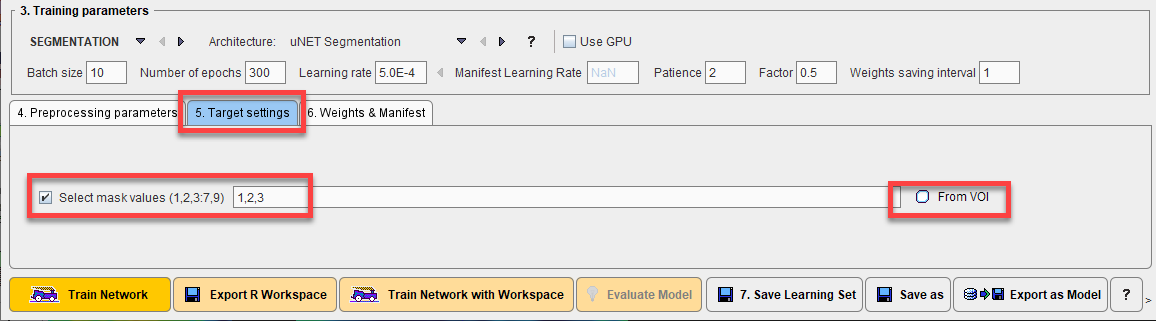
Definition of Target Settings
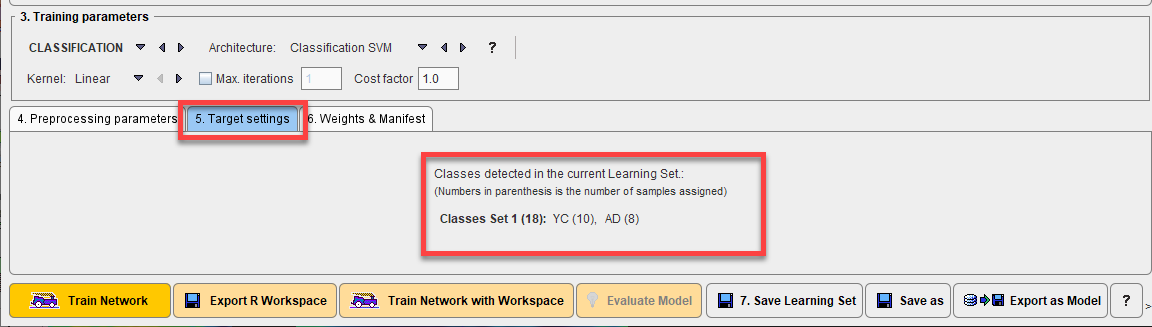
The target settings, defined on 5. Target Settings, that are required depend on whether a segmentation or classification task has been defined. For segmentation tasks a list of the integer labeled segments or VOI numbers to be used must be provided if more than one segment is present in the reference. The reference segment image may contain more segments than actually required. The option Select mask values allows the integer value of the required segments to be specified by entering the label values of the target segments, separated by a “comma”. The From VOI interface may be used where VOIs are available instead of or as well as segments.
For classification tasks the classes defined in the samples are reported. If the list of classes is incorrect the Project label per sample should be edited using the database interface.
Saving of Training Result
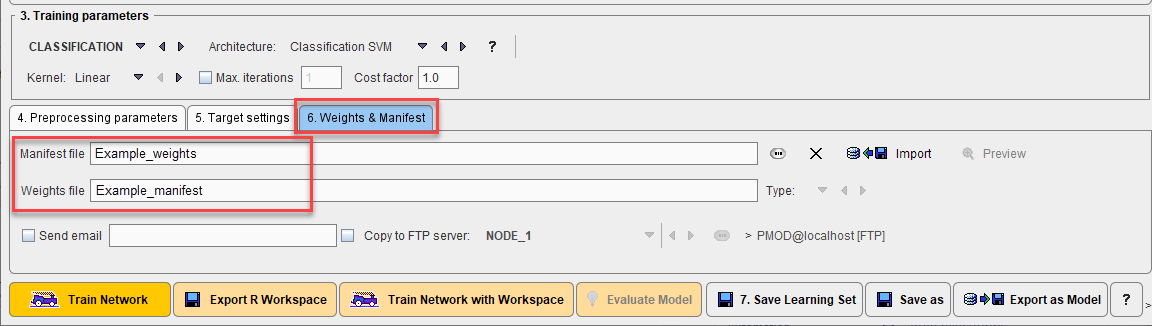
Two files result from a neural network training, Weights and Manifest. The Weights file contains the weighting given to each layer in the network. The Manifest file contains details of the Learning Set and the training process such as the samples used for training, samples used for validation (every fifth sample), number of epochs used, batch size, volume size, and the segments in the output. Weights and Manifest are inherently linked, and references to the Weights are included in the Manifest. Multiple Weights files may be created depending on the model architecture (e.g. Generative Adversarial Models, GAN).
The file locations are defined on the 6. Weights & Manifest panel, and the files will be logically attached to the current learning set. In case of Additive Training, these defined files provide the starting point for further training of the neural network with new samples.
Before starting training we recommend saving the learning set in its current state using 7. Save Learning Set. Save As may be used when editing an existing learning set (e.g. changing pre-processing parameters) and wishing to save it as a new copy in the database.
The Send email option is provided in case of training on cloud computing infrastructure. When training has been completed an email will be sent to the address provided (we suggest testing this functionality with a limited training run to ensure that your institutional firewall settings allow receipt of the email). The weights resulting from training (on cloud computing) may also be copied to an FTP server according to the settings provided.
Export as Model is used to save the required information to use a trained neural network for Prediction in the PMOD installation resources/pai folder. The resulting model in the architecture/weights folder can be copied to other PMOD installations. Import Model as described above is particularly useful for this purpose. Trained models can also be used for Prediction in the same PMOD installation without Export as Model, and will be available as Learning Sets in the database.