Segmentation of pathology or of organs/regions that do not conform to common templates can be a tedious, time-consuming and subjective procedure. The use of machine learning to automatically perform such a segmentation has the potential to save large amounts of time and improve reproducibility.
In the example shown below, regions of necrotic, gadolinium-enhancing and penumbra of a brain tumor are shown in color on a gray-scale anatomical T1-weighted MR image. Contrast from four MR series (T1-weighted, T2-weighted, T2-FLAIR, gadolinium-enhanced T1-weighted) were used to define these regions. For the top row, created by an expert reviewer using manual segmentation, this process takes many minutes or even hours. In the bottom row, the broadly similar segmentation result was generated by a trained convolutional neural network and took seconds.
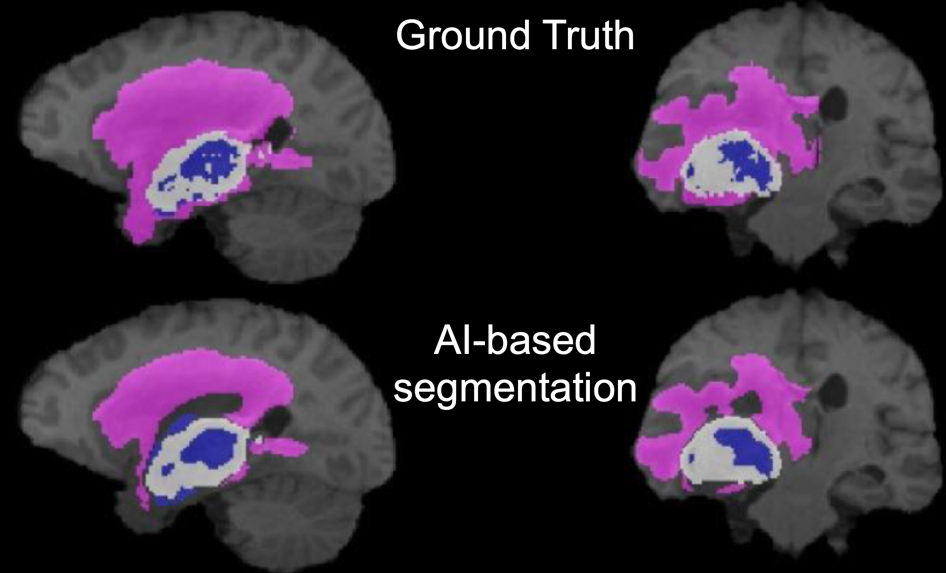
However, training a convolutional neural network to perform such a segmentation task requires a substantial amount of data, time and effort.
PMOD’s PAI framework aims to make training and deploying ML-based segmentation more accessible to non-expert users. PMOD’s well-tested tools for image processing and traditional segmentation provide an excellent base to prepare the training data needed for supervised machine learning.
In addition to AI-based segmentation, PAI also supports classification tasks. An example of classification in imaging is the assignment of a label “amyloid positive” or “amyloid negative” to amyloid PET images for tracers such as 11C-PiB. PMOD’s database functionality provides the base to organise data into classes for training of a neural network. The trained neural network then returns a probability of a new image belonging to a given class.