Data Consistency
A prerequisite of training a neural network is that all samples are consistent. For example, the MICCAI BraTS example described in the Multichannel MRI Segmentation (brain tumor) Case Study expects four input MR images, each from a particular type of MR sequence, and reference segments identifying three tissue types for segmentation. Adding a sample with only two input MR images, or reference segments with five labels provokes a failure. Likewise, prediction using the trained neural network will fail with data of a different structure.
In a classification project, all samples must have a Class assigned or a warning that unassigned samples are present will be returned and the samples excluded from training. During prediction the use of input data with different dimensionality to the data used for training will return a warning, as will missing VOIs used as part of data reduction in the SVM architecture (see Amyloid PET classification Case Study).
Manifest File
To ensure consistency, PAI uses a manifest file (JSON format) to store information about the training process and history. The consistency check includes the number and type of datasets included, their descriptions, as well as the pre-processing procedures. The manifest file is based on the first valid sample (“leading sample”) when the first training occurs. The manifest file is additionally associated with the weights file resulting from training of a model. If a mismatch between manifest and weights is detected when importing/retrieving these files in the Edit Learning Set dialog, a warning will be returned when additional training, or prediction, is attempted.
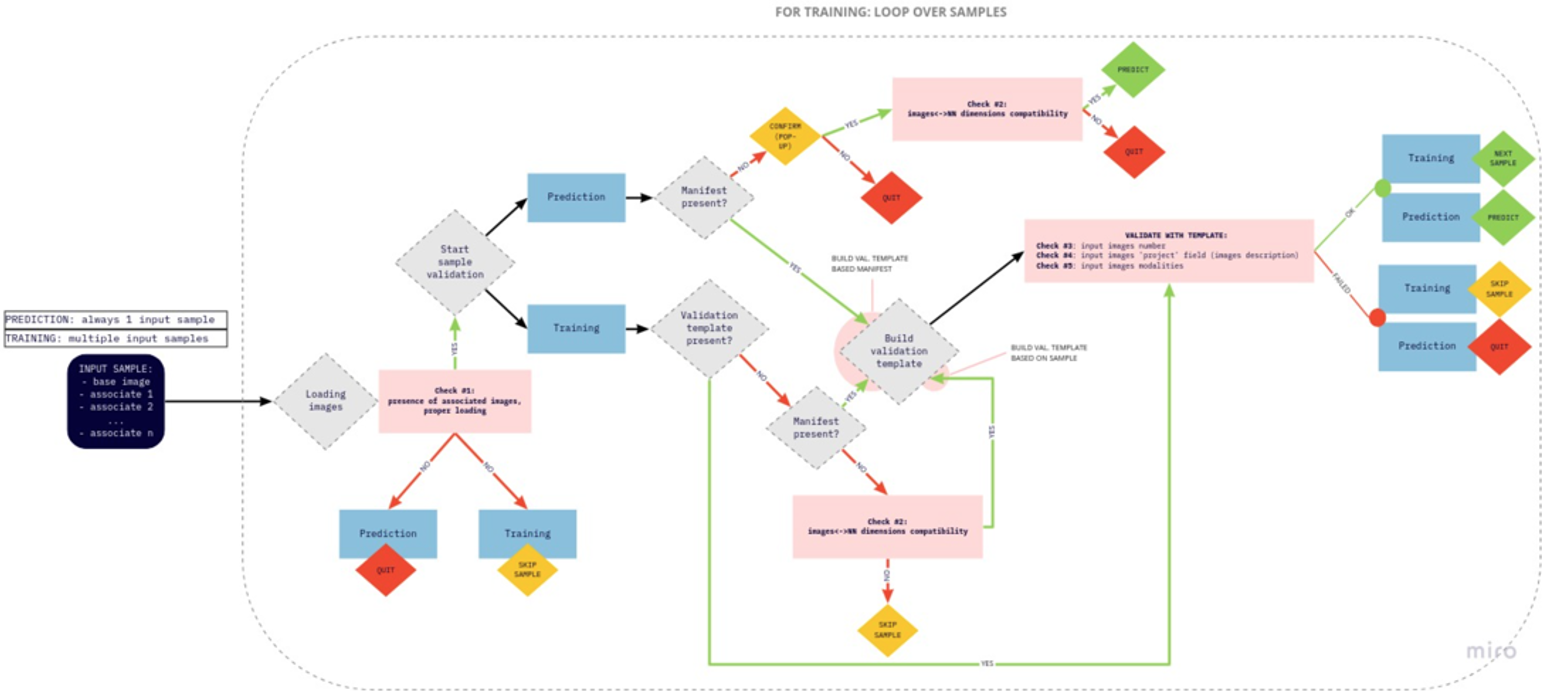
Data Checks
The following checks are included;
•Proper loading of the associated images – checking whether all associated images are properly loaded.
•Number of dimensions – the number of dimensions of the input images must be consistent with the number of dimensions of the images used for the original training. It must also be consistent with the number of dimensions supported by the chosen model.
•Number of associated images – the number of associated input images must be the same as the number of images associated in the samples used for the original training.
•Segmentation: “Project” field, serving as image description – the description of the associated input images stored in the “Project” database field must be the same as in the images used for the original training
•Classification: “Group” field, class assignment - the classes detected are reported before training is started and warnings are returned for samples missing a class, or if less than two classes are detected, or if the selected samples do not contain all classes detected in the learning set (manifest)
•Modalities – the modalities of the associated input images must be the same as for the images used for the original training.
If one of the above requirements is not met, PAI will do the following according to the workflow in use:
•Prediction: Cancel processing and inform the user
•Re-training: Skip the sample and print the information in the log
Model Configuration Check
The final control checks the settings in the user interface. Every time the user starts a training or saves the learning set, the content of the selected manifest file will be compared to the current settings in the user interface. This avoids accidental use of training parameters that differ from previous training sessions. The user is prompted to copy either all or only critical settings between manifest and learning set.
Control Overview
The data and model consistency checks are performed in the background during the workflows. Issues will be automatically detected and the user guided to correct them.