K-Means is a popular method which partitions N observations into K clusters. The parameters are the Number of clusters (=K), the Number of iterations of the heuristic procedure, and an assumed Percentage of background pixels.
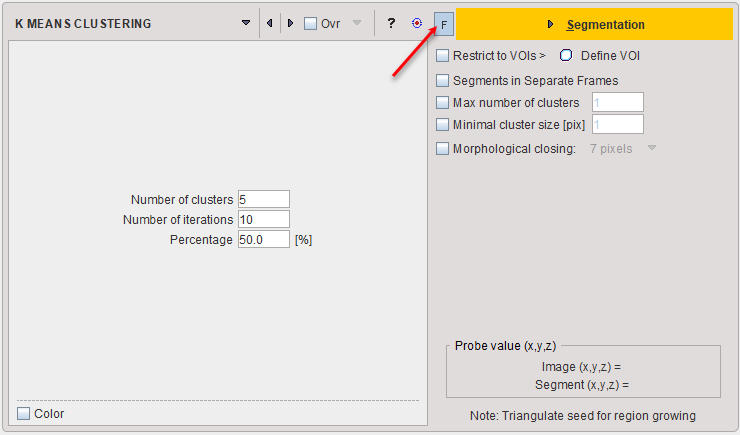
The procedure can be applied to static and dynamic data. In the latter case, pixel with similar signal shapes will be clustered using the time-weighted Euclidean distance as the measurement of dissimilarity (or distance) between TACs. Note that the F button has to be enabled, because otherwise each frame of the dynamic series will be clustered separately.
The procedure for clustering based on the signal shape proceeds as follows:
1.Background pixels are removed by calculating the signal energy of the pixel-wise TACs (sum of squared TAC values), and considering only pixels above a specified percentile.
2.K non-background pixels are randomly selected as initial cluster centroids .
3.Each non-background pixel is assigned to the centroid with minimal distance between the TACs, thus forming K initial clusters.
4.For each cluster a new centroid TAC is calculated as the average TAC of all pixels in the cluster.
5.An iterative process is started which repeats the following two steps:
(1) Each pixel TAC is compared with all centroid TACs and assigned to the cluster with minimal distance.
(2) All centroid TACs are recalculated to reflect the updated cluster population.
The iterations are repeated until no pixels are re-assigned to a different cluster, or a maximal number of iterations is exhausted.